When Google launched Gemini three years ago, the goal was to build a multimodal large language model — a single neural network that was trained on text, image, audio, and video and could generate content in any of those formats.
Today, at its Google I/O developer conference, the company took a concrete step toward that goal with Gemini Omni, a new family of multimodal models that Google CEO Sundar Pichai says will be able to “create anything from any input.”
Omni will start with video. Users can now combine images, audio, video, and text, and rather than simply stitching those inputs together, Omni reasons across all of them to produce a consistent output. The result is high-quality videos that reflect an understanding of physics, culture, history, and science.
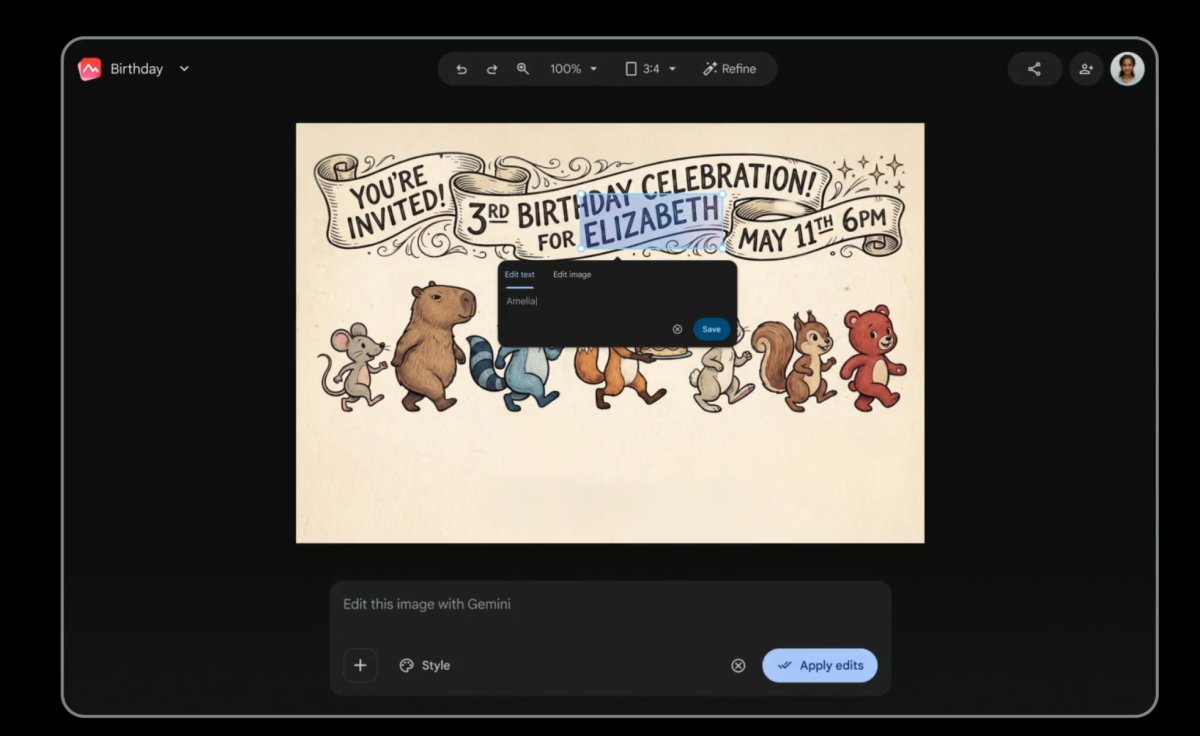
Omni also lets users edit photos with plain text commands rather than complex editing software, similar to Google’s Nano Banana.
Google already has a dedicated video model, Veo, that lets users turn text and images into videos, and even direct and customize avatars. But Google DeepMind director of product management Nicole Brichtova says that today’s release is more than a Veo update: “It’s the next step towards the progression of combining the intelligence of Gemini with the rendering capabilities of our media models.”
One example that Koray Kavukcuoglu, DeepMind’s chief technologist, gave reporters during a media briefing on Monday: When Omni was given a simple prompt like “a claymation explainer of protein folding,” it quickly rendered a video of a stop-motion explainer with a voice-over that said, “Proteins start as chains of amino acids. They fold into patterns like the alpha helix and flat sections called beta sheets, forming a perfect three-dimensional shape.”
The long-term vision for Omni is broader, involving the model being used to do things like generate images from audio, or audio from video.
“When we first announced Gemini, it was our first AI model to be natively multimodal,” Pichai said during the briefing. “We knew that training it on a combination of text, code, audio, images, and video would give it a deeper understanding of the world. With world models, AI is moving from predicting text to simulating reality. Gemini Omni is the next step in that direction.”
As part of the release, users will also be able to create videos with their own digital avatars — something OpenAI popularized on its now-defunct Sora app with Cameos. To prevent deepfakes, users will have to go through a dedicated product onboarding, which involves recording themselves and speaking out a series of numbers, per Brichtova. The avatar then gets stored for future use.
Additionally, all videos created with Omni will include Google’s SynthID digital watermark, which allows users to verify if videos were generated via the Gemini products.
The first model in the family is Gemini Omni Flash, which will roll out today to the Gemini app, YouTube Shorts, and AI creative studio Flow. Flash will be capable of rendering 10 seconds of video, which Brichtova says isn’t a model limitation, but rather a decision based both on a desire to get it into more hands and an anticipation that most users won’t want to make much longer videos yet. Longer video durations are in the pipeline for the near future, though.
Google seems to be pitching Omni Flash as more of a consumer tool. The examples Brichtova and Gabe Barth-Maron, a research engineer at DeepMind, gave on a call with TechCrunch of uses for digital avatars were all personal: Making a video of yourself winning an award or going to the moon, or removing a passerby from the background of a video you took on vacation.
Barth-Maron put it more simply: “They’re like personalized memes.”
“We definitely did focus on making this easy to use for consumers,” Brichtova said. “Not many video models have breached that chasm with consumers, so this is our play to do that.”
The ease of use comes with a caveat: Brichtova and Barth-Maron noted that editing prompts will need to be highly specific, otherwise Omni risks over-editing or unintentionally altering elements the user wanted to keep — a problem Nano Banana users would have run into.
Despite the near-term consumer focus, Omni’s enterprise and creative implications are obvious, and Google will make Omni available via API in the coming weeks. The avatar-generating tool — a capability that is available today on Shorts — is something Google expects content creators to pick up. But more broadly, an end-to-end multimodal workflow could be transformative for advertisers and filmmakers.
Startup Luma AI is building something similar, an agentic tool that can generate an entire ad campaign based on a short brief and a product image, powered by its own “unified” model.
“We’re actually pretty proud of the model’s text-rendering capabilities, which is really useful for things like advertising,” Brichtova said. “If you want a product somewhere, or even just a slogan, it needs to be accurate … We definitely anticipate filmmakers and other kinds of creators are going to be using this model as well.”
The more professional use cases might be better served by the Omni Pro model, which should perform better across all Omni tasks. Google hasn’t said when it will release Pro yet, but Brichtova said that will happen when “we feel like we’re at a point where we have a step change above Flash.”
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.